By 2026, most banks, fintechs, and payment players will be running real‑time payment rails, richer digital channels, and far more complex partner ecosystems than today. Yet the detection rate for illicit flows will still be embarrassingly low unless transaction monitoring (TM) changes shape, not just technology.
The uncomfortable baseline is familiar. Global estimates suggest that less than one percent of illicit financial flows are seized or frozen. Compliance costs keep rising, but conversion of alerts into substantive cases has not improved at the same pace. What most institutions have is not a lack of models but a stack of disconnected controls, legacy rule sets, and partially deployed machine learning that never quite made it past “pilot.”
If you are designing a TM roadmap for 2026, the question is no longer “Should we use AI?” but “Exactly where does AI add signal, where does it add noise, and how do we connect it to KYC, screening, and case management in a way that will stand up to regulators?”
This article takes a practitioner view grounded in what we see at KYC Hub and in current regulatory and industry work: what is technically feasible, what is already working in production, and how a real 2026 deployment is likely to look.
Several structural shifts mean institutions cannot keep tweaking legacy rule engines and hope for a different outcome.
Fast payment systems and UPI‑style schemes are becoming standard infrastructure, with 24/7 settlement and near‑immediate irrevocability. The World Bank and central banks flag that instant payments materially increase fraud risk and compress the time available to detect and intervene. APP scams, UPI velocity abuse, and “pay now, disappear” merchant fraud are all consequences of this shift. Traditional overnight batch TM is structurally mismatched to this environment.
Supervisors are explicitly pushing institutions toward risk‑based, technology‑enabled AML programmes. FATF’s work on new technologies notes that advanced analytics and digital identity can make AML/CFT measures faster, cheaper, and more effective if deployed under sound governance. In the United States, FinCEN’s 2024 proposal to modernise AML/CFT programmes codifies ongoing risk assessment, better use of data, and alignment with national priorities, and it explicitly references the role of emerging technologies.
In parallel, the EU AI Act will classify many AI‑driven AML and fraud tools as “high‑risk” systems, requiring stronger controls on data quality, documentation, monitoring, and human oversight. AI in TM is no longer a lab experiment; it is a regulated capability.
Generative AI could add $200–340 billion of annual value to global banking, largely through productivity gains. Supervisors in Europe already highlight how AI models in fraud detection improve real‑time pattern recognition. Major schemes like Visa report tens of billions in attempted fraud blocked each year through AI investments.
Cloud, GPUs, and mature open‑source stacks mean that banks no longer need heroic engineering just to run gradient‑boosted trees or graph algorithms in production. The bottleneck has shifted from “Can we run it?” to “Can we feed it and govern it?”
The Monetary Authority of Singapore’s FEAT principles (Fairness, Ethics, Accountability, Transparency) and the Veritas Toolkit 2.0 offer concrete methods for validating AI use‑cases in finance, including AML scenarios. That type of framework is increasingly what boards and regulators expect: prove your AI does something useful, does not introduce new unfairness or bias, and can be explained.
For KYC Hub and our customers, this creates a pragmatic constraint set. By 2026, any TM innovation must be explainable, auditable, and well‑connected to customer risk and KYC data, not a black‑box detector bolted on the side.
A 2026 TM stack is not “rules versus AI.” It is a set of complementary tools wired together around a high‑quality KYC and transaction data hub.
Rules and scenarios remain the explicit encoding of typologies and regulatory expectations. They are good at:
In practice, most institutions will continue to run 30–80 scenarios, but the way they manage them will change. Instead of one‑off tuning, rules sit inside a Holistic / Dynamic Risk Assessment (DRA) framework: thresholds differ by segment, customer risk rating, and product, and are continuously updated using data‑driven feedback.
Supervised models work best when you have labelled outcomes: confirmed fraud, SARs filed, SARs closed with no action, merchant terminated, and so on. In TM, supervised ML is effective for:
Gradient‑boosted trees and similar models usually offer a good balance of performance and explainability. Their job is to re‑order the work, not to unilaterally block or clear activity.
The main constraint is label quality. Many historic cases are “suspected, not proven,” and many SARs are filed as defensive reporting. A 2026‑ready stack explicitly models label noise and uses techniques like weak supervision or human‑in‑the‑loop relabelling rather than treating all historical decisions as ground truth.
Unsupervised approaches are valuable where you lack labelled data or where patterns shift quickly. They support:
You are not blindly blocking anomalies. Instead, you use anomaly scores as inputs into DRA, thresholds, and case creation.
Money laundering, mule networks, and marketplace fraud are network problems. Graph analytics lets you move from “this transaction looks odd” to “this node sits in a suspicious network.”
Practical 2026 use‑cases include:
Graph algorithms like community detection, PageRank‑style influence scores, and path‑finding become part of the scoring pipeline. Network analysis also supports entity resolution and a true “single customer view,” which is why KYC Hub invests heavily in building a clean entity graph that combines onboarding, KYC, screening, and transactional relationships.
Large language models are not good at deciding whether to file a SAR. They are very good at making humans faster and more consistent.
By 2026, the realistic LLM uses in TM are:
All of this must run inside the institution’s perimeter or on a tightly controlled deployment, with prompts and case data kept out of public models. Responsible AI frameworks like FEAT/Veritas and the EU AI Act’s transparency expectations will push institutions toward private or fine‑tuned models with strong logging and guardrails.
Reinforcement learning (RL) is rarely the first tool a TM team reaches for, but it is powerful when used to optimise decision policies around clear cost functions.
Typical 2026 RL applications include:
The critical element is reward design. If you reward only volume reduction, you will get aggressive suppression and missed risk. If you reward only detections, you will overwhelm operations. A 2026 deployment treats RL as a carefully governed optimisation layer, not a free‑running black box.
In a modern stack, KYC, TM, graph analytics, LLMs, and RL sit in a single flow:
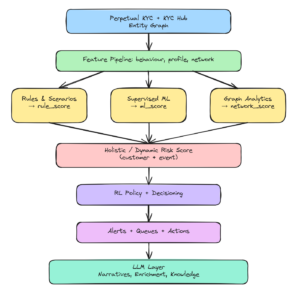 Abstract architectures are less useful than concrete patterns. The following scenarios illustrate how a 2026‑ready stack behaves, based on what we see across banks, fintechs, payment processors, and KYC Hub implementations.
Abstract architectures are less useful than concrete patterns. The following scenarios illustrate how a 2026‑ready stack behaves, based on what we see across banks, fintechs, payment processors, and KYC Hub implementations.
A new e‑commerce merchant goes live and, within an hour, starts receiving a series of low‑value card‑not‑present (CNP) payments from multiple issuers, most of them first‑time card‑merchant pairings.
In a 2026 deployment:
The outcome is targeted friction for an emerging fraud typology, without a blanket block on all new merchants.
In UPI‑style systems, fraudsters typically pull funds from multiple victims into a cluster of mule accounts, and then cash out quickly through ATMs, crypto off‑ramps, or cross‑border remittance rails.
A hybrid AI‑enabled TM system will:
Here, the single customer view is no longer optional. Without a consolidated KYC and transaction hub, it is almost impossible to see that four consumer accounts at different institutions are, in practice, one mule network.
Acquirers and PSPs struggle with merchants that are, in reality, fronts for high‑risk activities or laundering. By 2026, effective stacks will:
This is where a platform like KYC Hub is often positioned: as the connective tissue between onboarding, ongoing KYC, and TM, ensuring that when TM flags a merchant, the KYC view is already enriched and up to date.
A classic layering pattern involves funds moving from retail accounts in one region through small businesses, correspondent banks, and finally into high‑risk jurisdictions, often using multiple currencies and payment types.
A 2026‑grade TM deployment will:
This is not science fiction. The building blocks exist; the gap is disciplined integration and governance.
Knowing what fails in production is as important as knowing what works. Most AI‑for‑TM disappointments fall into a handful of patterns.
Many supervised models are trained on SAR filings or internal case outcomes treated as binary truth. In reality, SARs are often filed defensively, and “no SAR” does not equal “no risk.” Without explicit modelling of uncertainty and structured relabelling exercises, models learn to mimic historical behaviour rather than improve on it.
Several institutions attempt to deploy ML before fixing basics: entity resolution, missing fields, inconsistent product codes, or fragmented KYC records. The result is models that embed legacy data flaws and cannot generalise.
By contrast, teams that invest first in a KYC and transaction hub—clean entity graph, standardised taxonomies, clear data lineage—see better returns from even simple models. This is the foundational layer KYC Hub typically builds jointly with clients before switching on more advanced analytics.
AML and fraud patterns change faster than most model monitoring cadences. Without robust feature drift detection, champion‑challenger setups, and periodic back‑testing, models quietly degrade. Overfitting to the training period leads to brittle detectors that break when a new product or rail is launched.
Graph analytics can be powerful, but it is easy to:
A pragmatic approach is to start with narrow graph‑based use‑cases (mules, shell entities) and gradually expand, with clear rules on what kinds of nodes and edges are included.
LLMs will, by design, confidently invent facts if asked to opine beyond their input context. Typical pitfalls in TM include:
Mitigation is straightforward but non‑negotiable: retrieval‑augmented generation constrained to approved internal sources, strong red‑teaming and hallucination tests, and clear policies on what an LLM is allowed to decide versus merely draft.
RL failures are almost always reward‑design failures. If you reward an agent primarily for reducing alert volume, it may learn to shift thresholds upwards across the board, masking genuine risk. If you ignore customer complaints or regulatory findings in your reward definition, the agent will optimise against a distorted picture of reality.
An effective 2026 programme treats RL as a controlled experiment with explicit approval gates, not as autonomous optimisation.
Finally, many programmes underestimate the organisational work: model risk management, change control, and cross‑functional ownership. As regulators sharpen expectations on high‑risk AI, AML models will need the same level of documentation, validation, and independent review as credit risk models.

Putting this together, what would a credible AI‑enabled TM deployment actually look like in 2026?
The core asset is a risk data hub that KYC, TM, screening, and fraud all share:
On top of the hub, a layered analytics stack runs:
Critically, these components are composed rather than siloed; they produce scores and signals that feed a common risk‑scoring framework.
A mature 2026 programme will have:
From KYC Hub’s vantage point, the institutions that move fastest are the ones that treat AML analytics as product development: iterative, measured, and jointly owned by risk, compliance, data, and engineering, rather than a one‑off change request to a vendor.
In 2026, effective TM teams will look different:
Hiring and upskilling this mix is often harder than buying technology.
Summarising all of this, three principles define AI in TM that will actually work by 2026.
First, data and identity before models. Without a high‑quality data hub—clean entities, perpetual KYC, and unified transaction data—AI will mostly learn your existing blind spots. With it, even relatively simple models can materially lift detection and efficiency.
Second, hybrid stacks over silver bullets. Rules, supervised and unsupervised ML, graph analytics, LLMs, and RL each have clear, distinct roles. The winning pattern is an engineered system where each tool does what it is good at, and where human analysts remain firmly in the loop for high‑impact decisions.
Third, governance and explainability as design constraints. AI that cannot be explained, monitored, and aligned with regulatory expectations will either be blocked by internal stakeholders or create unacceptable risk. Building under responsible AI frameworks from day one—rather than retrofitting controls—is both safer and faster.
For KYC Hub, this is the lens we apply when we work with banks, fintechs, payment companies, and crypto platforms: start from concrete risks and data reality, design the hybrid stack around a strong KYC and entity backbone, and then introduce AI in layers that can be measured, governed, and iterated.
Book a TM review session with KYC Hub to discuss how to implement an AI‑enabled transaction monitoring stack for your institution.

When developing and implementing a transaction monitoring system, it is crucial to have a...
Read More
Explore the critical role of transaction monitoring in mitigating financial crimes, such as money...
Read More
Discover the impact of high false positive rates and explore strategies to reduce false...
Read More